前言
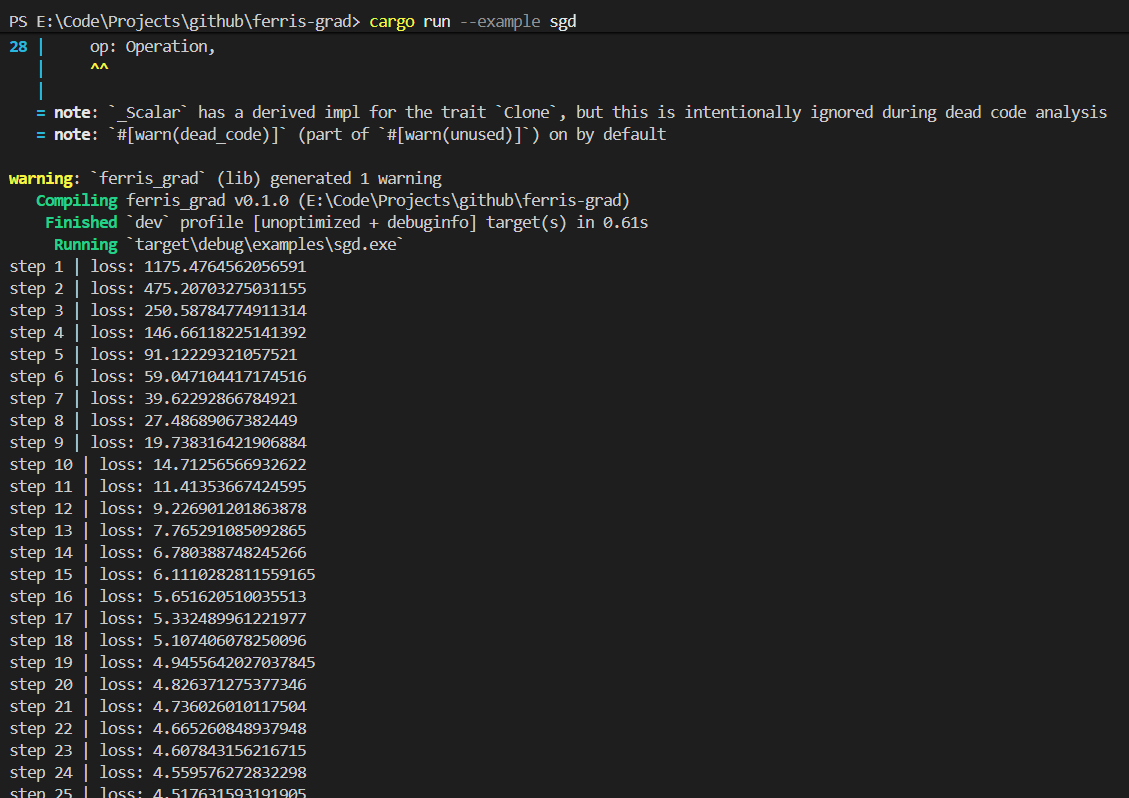
最近读了很多深度学习相关的paper,是时候写些东西记录一下了。本文我会带大家一步一步地用rust构建出一个自动微分库,这是实现神经网络训练的基础,然后基于这个库构建一个最经典的多层前馈神经网络(MLP), 训练过程如图:
源代码地址:
https://github.com/StepfenShawn/ferris-grad
神经网络训练的核心问题
神经网络要解决的问题是要在给定输入数据集X和输出数据集Y中学习, 目的是让计算机通过在数据中找到某些规律后执行复杂任务(
如识别、预测、决策
)。
那么它是怎么工作的呢? 实际上是一个数学公式,我们可以把它学习的过程看做是一个复杂函数, 输入数据$X$和一堆权重向量$w_1, w_2, …, w_i$, 得到输出$Y$:
$Y = f(X, w_1, w_2, …, w_i)$
无论这个函数的计算过程有多复杂,都可以分解成一系列的基本算数运算(±*/)和基本函数(三角函数,对数函数,指数函数等)。
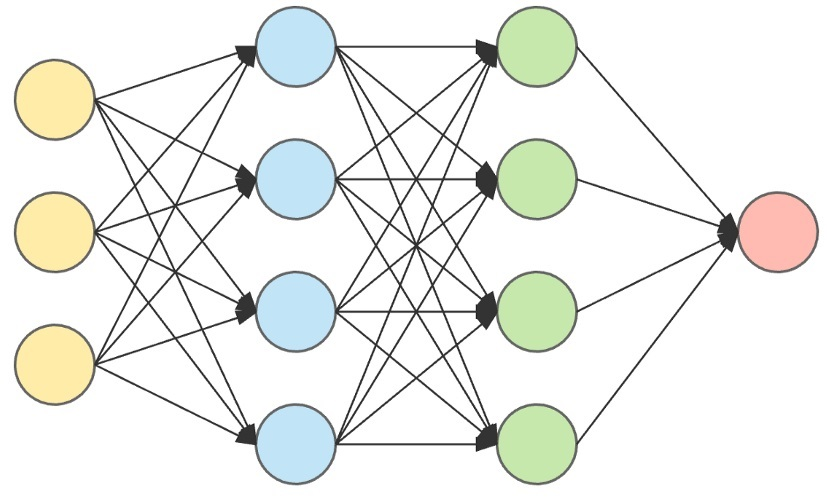
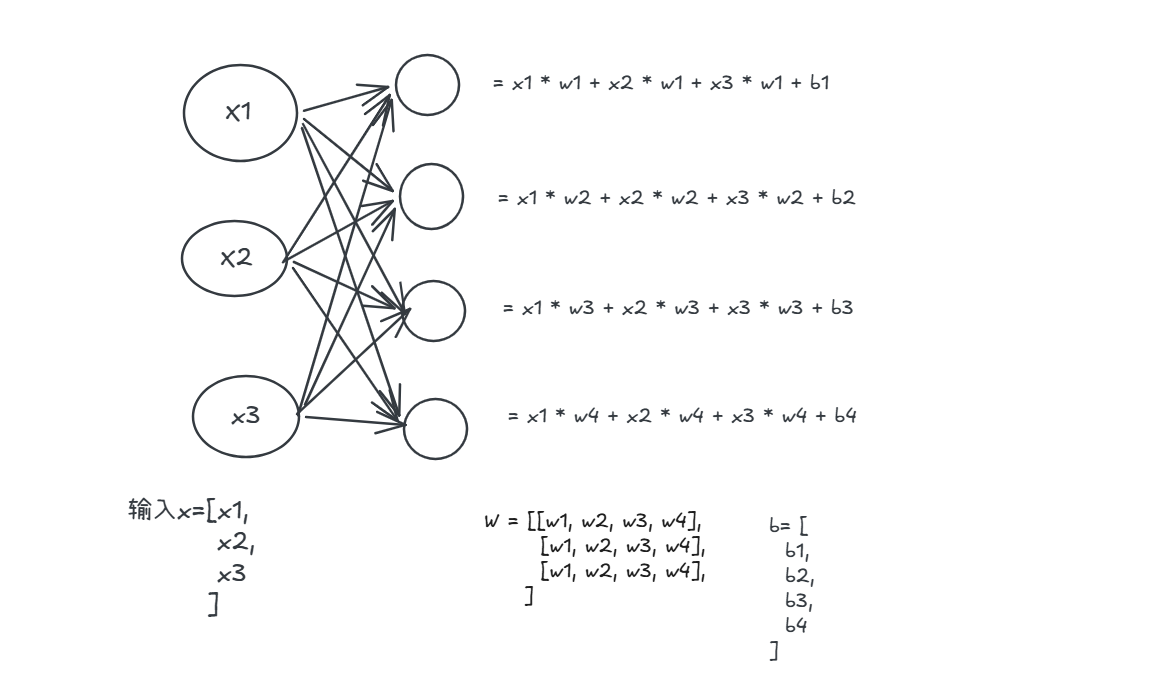
例如上面是一个4层的神经网络, 输入是一个31的向量, 有两个隐藏层分别有4,4个神经元, 然后输出成为一个神经元, 为了方便计算,我们一般会把整一层的神经元权重抽象成一个向量, 根据如图神经网络的结构, 第一层的权重$w_1$是一个43的矩阵,那么输入$X$经过第一层会经过以下的计算:
$f_1(x) = w_1 * x + b$
注意到我们输入的$x$是一个矩阵,所以$w_1 * x$意味着每一个神经元的权重都对$X$中的每一个元素进行了线性组合计算, 上图神经元之间的连线就代表了这个意思:
为了网络能够拟合一些非线性函数, 一般我们还会设置一个激活函数$g$, 比如说$tanh$, 那么式子就变成了:
$f_1(x) = tanh(w_1 * x + b)$
计算得到$y_1 = f_1(x)$, 就将$y_1$输入到下一层$f_2(y_1)$计算, 以此类推。
而反向传播是神经网络训练过程中的重要一步,当我们的网络计算到最后一层$y_n = f_n(y_{n-1})$时, 而真实数据集输出应该为$Y$, 这时我们根据一个损失函数$Loss(y_n, Y)$计算误差, 从而反过来更新权重$w_1, w_2, …, w_i$,使得误差值变小。
这就是神经网络训练的核心问题——“改变某个参数,损失(误差)会怎么变化?”
数学上,这叫做求导(计算梯度):
$$\frac{\partial L}{\partial w} = \text{“改变 } w \text{ 一点点,损失 } L \text{ 会变多少”}$$
于是我们可以实现一个库自动帮算出每个参数的梯度,然后就可以朝着"误差减小"的方向调整参数。
用图结构表示计算过程
因为这个库要自动算出每个参数的梯度, 所以每次做运算,我们不只是算出结果,还要记录这次运算的历史。
比如说:
1 | let a = Scalar::from_f64(2.); |
这段代码在内存里建立了这样一张图, 图中的每一个节点代表着一个数字,边代表了计算关系:
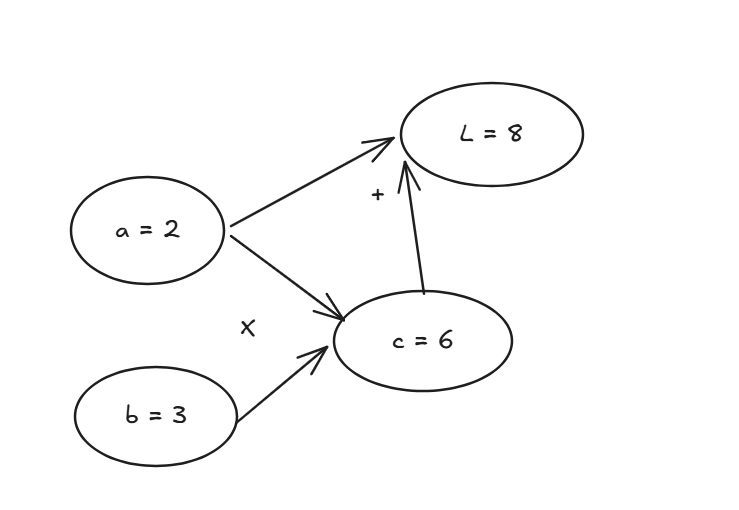
在这个库中,我们会实现一个图结构, 每个节点都记住了自己的"父节点"。
有了这个图结构后, 还有一个最大的好处是可以方便地进行反向传播, 比如我想知道, 如果$l$的值变化了0.001, 那么$a$和$b$分别变化了多少? 于是我们就可以在这张图上面进行从$l$开始进行拓扑排序计算梯度:
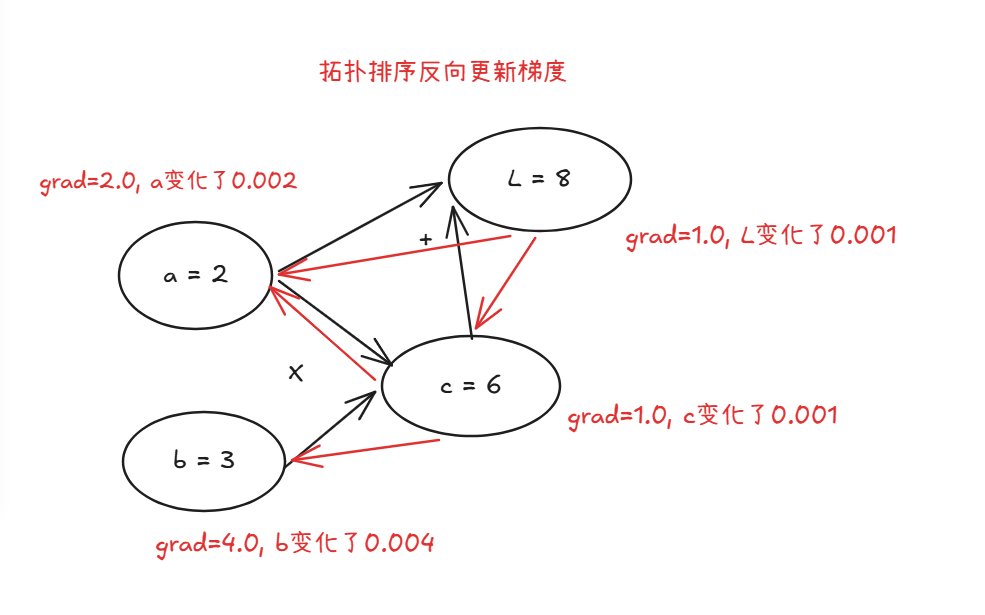
在我们接下来实现的库中, 只需要调用l.backward(), 有了计算图,我们就可以自动算出$a$和$b$的梯度了:
1 | l.backward(); |
那么梯度是怎么计算出来的呢? 是基于导数的链式法则。
什么是链式法则? 对于一个复合函数$f(g(x))$, 我们要求$\frac{\partial f}{\partial x}$:
$$
\frac{\partial f}{\partial x} = \frac{\partial f}{\partial g} \cdot \frac{\partial g}{\partial x}
$$
这个公式其实很容易理解, 也就是把局部变化率乘起来组合成整体变化率,举个例子: 单车的速度是人的2倍, 汽车的速度是单车的4倍, 那么
汽车相当于人的速度倍数 = 汽车对单车的倍数 * 单车对人的倍数 = 8。
回到我们上面的例子:
$l = c + a$,$c = a \times b$,我们想知道 $l$ 对 $a$ 的梯度。
这很显然是一个复合函数求导问题, 根据链式法则:
$$\frac{\partial l}{\partial a} = \frac{\partial l}{\partial c} \cdot \frac{\partial c}{\partial a} + \frac{\partial l}{\partial a} = 1 \cdot b + 1 = b + 1$$
代入 $b = 3$,得到 $\frac{\partial l}{\partial a} = 4$。
设计架构
我们的架构非常简单,整个库由3个文件组成:
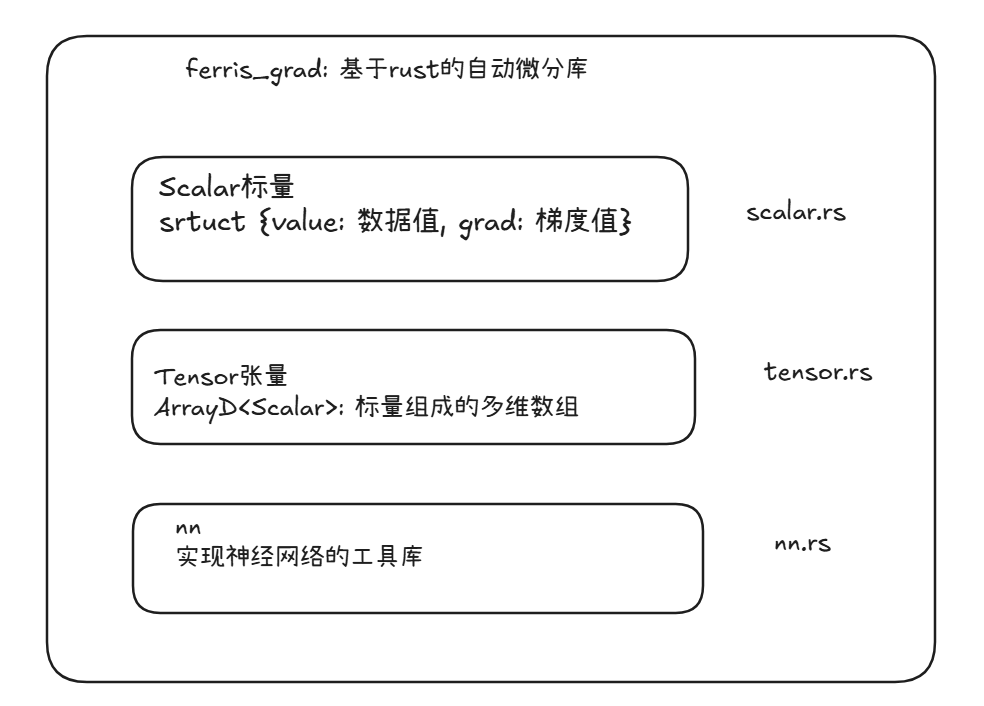
实现标量 —— scalar.rs
Scalar 是这个库最基础的类型,代表一个带有"梯度"的数字:
1 | // src/scalar.rs |
因为我们要实现一个图结构, 在rust里面最常用的方式是用Rc<RefCell<…>>来包装实现我们的Scalar:
1 | pub struct Scalar(Rc<RefCell<_Scalar>>); |
至于为什么用Rc<RefCell<…>>, 是为了让Rust编译器保证借用检查器在运行时检查,而不是在编译时检查,简单理解:
Rc:让多个地方可以共享同一个 Scalar(引用计数)RefCell:让我们可以在运行时修改里面的值(比如更新梯度)
实现计算图
加法的实现:
1 | // src/scalar.rs |
数学解释:
如果 $c = a + b$,那么:
$$\frac{\partial c}{\partial a} = 1, \quad \frac{\partial c}{\partial b} = 1$$
所以当误差 $L$ 对 $c$ 的梯度是 $\frac{\partial L}{\partial c}$ 时,根据链式法则:
$$\frac{\partial L}{\partial a} = \frac{\partial L}{\partial c} \cdot \frac{\partial c}{\partial a} = \frac{\partial L}{\partial c} \cdot 1 = \frac{\partial L}{\partial c}$$
$$\frac{\partial L}{\partial b} = \frac{\partial L}{\partial c} \cdot \frac{\partial c}{\partial b} = \frac{\partial L}{\partial c} \cdot 1 = \frac{\partial L}{\partial c}$$
相当于把梯度直接"穿透"加法节点,原封不动传给两个父节点。
乘法的实现:
1 | fn mul(a: &Scalar, b: &Scalar) -> Scalar { |
数学解释:
如果 $c = a \times b$,那么:
$$\frac{\partial c}{\partial a} = b, \quad \frac{\partial c}{\partial b} = a$$
所以:
$$\frac{\partial L}{\partial a} = \frac{\partial L}{\partial c} \cdot b$$
$$\frac{\partial L}{\partial b} = \frac{\partial L}{\partial c} \cdot a$$
幂运算pow的实现:
$$y = x^n$$
$$\frac{\partial y}{\partial x} = n \cdot x^{n-1}$$
1 | pub fn pow(&self, other: &Scalar) -> Scalar { |
自然对数的实现:
$$y = \ln(x)$$
$$\frac{\partial y}{\partial x} = \frac{1}{x}$$
1 | pub fn log(&self) -> Scalar { |
指数函数的实现:
$$y = e^x$$:
$$\frac{\partial y}{\partial x} = e^x$$
1 | pub fn exp(&self) -> Scalar { |
ReLU 激活函数 $y = \max(0, x)$:
$$\frac{\partial y}{\partial x} = \begin{cases} 1 & \text{if } x > 0 \ 0 & \text{if } x \leq 0 \end{cases}$$
1 | pub fn relu(&self) -> Scalar { |
定义好各种运算后, 接下来我们来实现反向传播, 我们用**广度优先遍历(BFS)**来实现拓扑排序:从输出节点出发,一层一层往回传梯度:
1 | // src/scalar.rs |
实现Tensor —— tensor.rs
单个 Scalar 只能处理一个数字。但很多情况下,我们的数据是矩阵(比如 100 张图片,每张 28×28 像素)。
Tensor 就是一个多维数组,里面每个元素都是 Scalar。
1 | // src/tensor.rs |
有了Tensor的结构后, 我们接下来实现Tensor点积(dot product),也就是矩阵乘法:
1 | pub fn dot(&self, other: &Tensor) -> Result<Tensor> { |
因为每个元素都是 Scalar,所以这里的乘法和加法都会自动记录计算图,很好的保证了梯度可以自动传播。
实现神经网络层 —— nn.rs
Linear 层(全连接层)
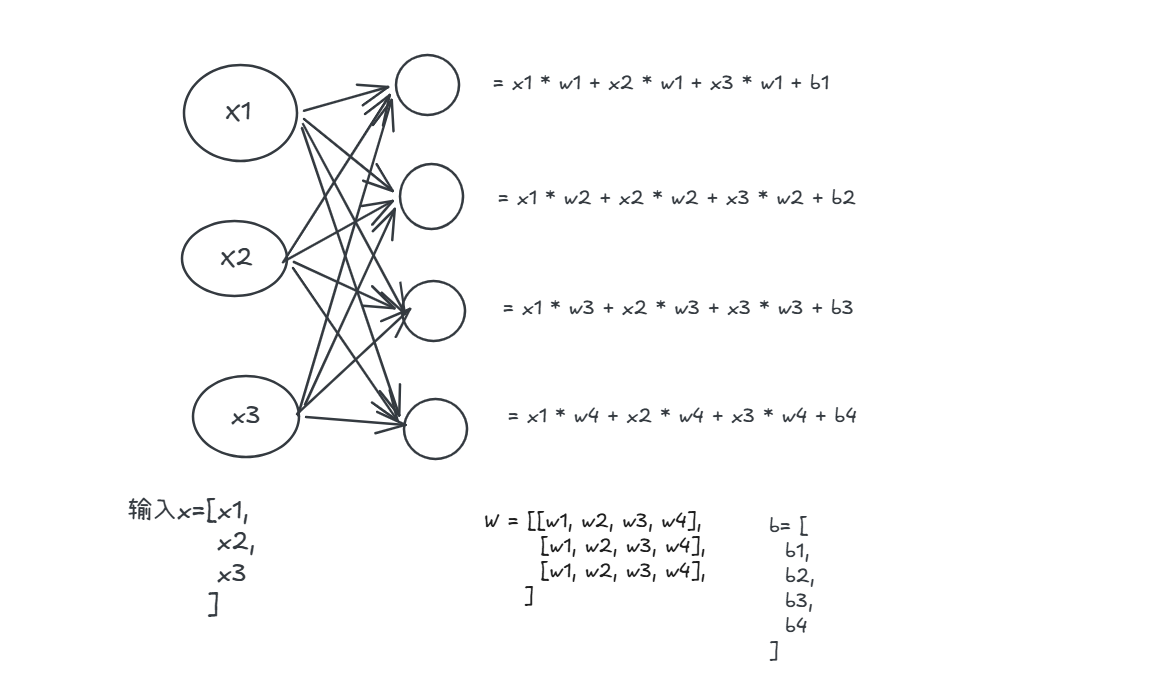
一个 Linear 层就是:
$$\text{输出} = \text{输入} \times W + b$$
其中 $W$ 是权重矩阵,$b$ 是偏置向量。
1 | // src/nn.rs |
前向传播:
1 | impl Module for Linear { |
MLP(多层前馈神经网络)
MLP 就是把多个 Linear 层串联起来:
$$x_1 = \text{Linear}_1(x_0)$$
$$x_2 = \text{Linear}_2(x_1)$$
$$\vdots$$
$$\text{输出} = \text{Linear}n(x{n-1})$$
1 | pub struct MLP { |
训练一个神经网络
接下来是时候用我们的库训练一个神经网络了, 首先我们准备数据:
1 | // 4 个训练样本,每个有 3 个特征 |
然后定义网络的结构:
1 | let mut network = MLP::new(vec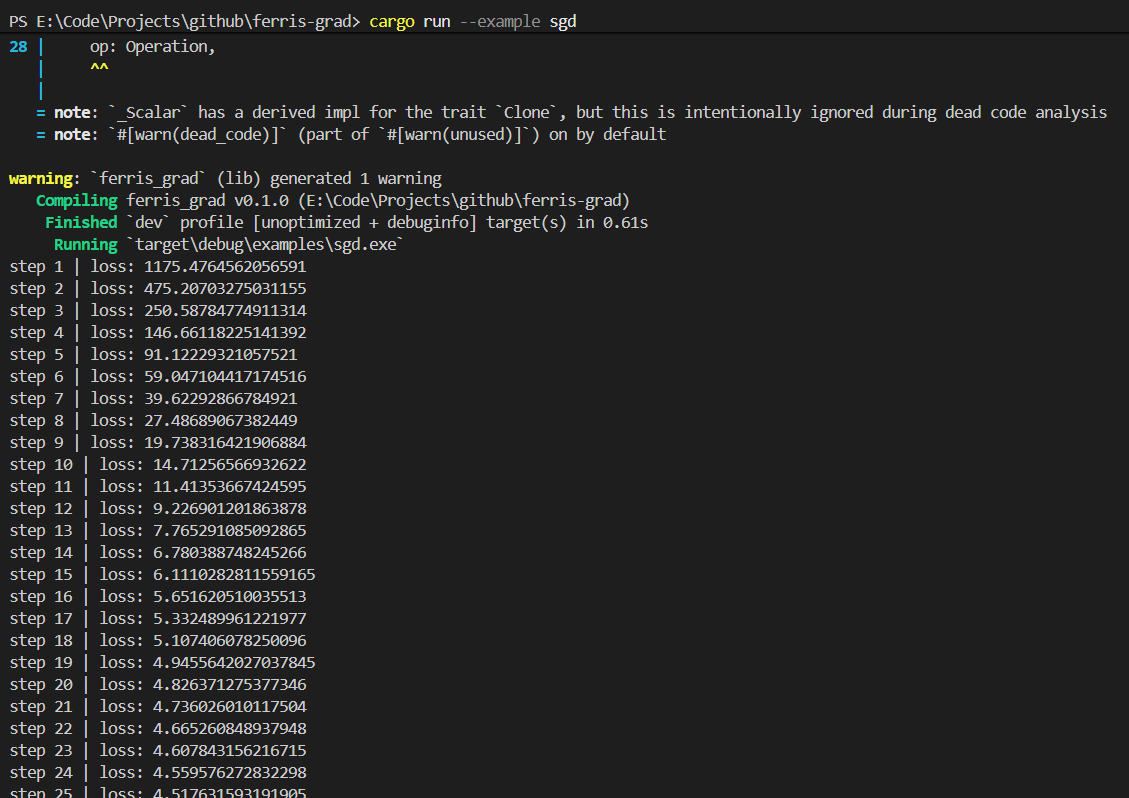
接下来我们输入一个简单的数据推理一下我们的模型:
1 | let input = Tensor::from_vec( |
于是在控制台可以看到对于[1.0, 1.0, 1.0]推理得到的结果:
总结
这个库的设计灵感来自 Andrej Karpathy 的 micrograd,结合了自己的理解用 Rust 重新实现了一遍,并加上了 Tensor 支持, 接下来研究一下怎么把Tensor跑在GPU上,该文章还会有后续, 请大家点个关注! 如有错误欢迎指出!